BLOG
VEJA AS NOVIDADES DA COMUNICAÇÃO DIGITAL
voltarInovação
Qual o próximo passo das gigantes de TI na Inteligência Artificial?
Publicado em 24/05/2017 - Fonte: http://idgnow.com.br/ti-corporativa
A Inteligência Artificial é a nova fronteira de concorrência acirrada em TI, com Microsoft e Google exibindo poderosas e sempre disponíveis ferramentas para empresas usuárias em suas respectivas conferências de desenvolvedores, Build e I/O, em maio.
Compreensível. A Inteligência Artificial já pode johgar melhor do que qualquer humano - e até mesmo dirigindo um carro melhor do que muitos de nós. Essas performances sobre-humanas, embora em campos limitados, são todas possíveis graças à aplicação de décadas de pesquisas, começando agora a deixar os laboratórios.
As tecnologias de voz ativadas por Inteligência Artificial por trás de assistentes virtuais como o Siri, da Apple, a Cortana, da Microsoft, o Alexa, da Amazon.com e o Google Assistant, embora ainda ofereçam desempenho inferior ao dos humanos, também exigem muito menos poder do que um supercomputador para rodar. As empresas podem mergulhar nas bordas desses avanços, por exemplo, desenvolvendo "habilidades" Alexa que permitam que aos proprietários do Amazon Echo interagir com elas sem ter que discar para o seu call center, ou navegar pelo site, apenas usando reconhecimento de voz baseado em nuvem.
Alguns dos primeiros trabalhos sobre Inteligência Artificial procuraram modelar explicitamente o conhecimento humano do mundo de uma forma que os computadores pudessem processar e raciocinar, se não entender o que está ao seu redor. Isso levou à comercialização dos primeiros "sistemas especialistas" baseados em texto. Esses primeiros sistemas não aprenderam pela experiência ao longo de sua carreira. Em vez disso, a experiência foi alimentada por muitos dados, seguindo um processo laborioso de seres humanos entrevistando outros seres humanos e destilando seu conhecimento implícito em regras explícitas.
Os maiores avanços na pesquisa de Inteligência Artificial nos últimos anos, e os mais aplicáveis no mundo corporativo, envolveram máquinas aprendendo com a experiência para ganhar seu conhecimento e compreensão. As melhorias na aprendizagem de máquina conduziram a mais uma derrota de um campeão de Go pelo AlphaGo, um programa desenvolvido pela DeepMind, subsidiária do Google. Esta semana, o jogador número 1 do mundo, Ke Jie, perdeu a primeira de uma série de três partidas contra a máquina. A vitória do AlphaGo foi por apenas meio ponto de diferença, uma marca do estilo de jogo do programa do DeepMind, que se importa mais com movimentos que lhe deem mais chances de vencer do que com o placar em si.
A aprendizagem da máquina começou com a criação de redes neurais - modelos computacionais que imitam a forma como as células nervosas, ou neurônios, transmitem informações ao redor de nossos corpos. Nosso cérebro contém cerca de 100 bilhões de neurônios, cada um conectado a cerca de 1 mil outros. Uma rede neural artificial modela uma coleção dessas células, cada uma com suas próprias entradas (dados de entrada) e saídas (os resultados de cálculos simples nesses dados). Os neurônios são organizados em camadas, cada camada tomando a entrada do anterior e passando sua saída para o próximo. Quando a rede resolve corretamente um problema, um peso adicional é dado às saídas dos neurônios que previu corretamente a resposta, e assim a rede aprende.
Redes com muitas camadas - as chamadas redes neurais profundas - podem ser mais precisas. Eles também são computacionalmente mais caras. Eles foram salaos de ser uma curiosidade de pesquisa pela capacidade de processamento paralelo da GPU, usada anteriormente principalmente para o processamento de jogos.
Os transistores estão fazendo isso por si mesmos
Esses avanços estão dando às empresas novas formas de lidar com seus grandes problemas de dados - mas criar a tecnologia necessária é, até certo ponto, um grande problema de dados em si.
Um de nossos pontos fortes é que podemos aprender com apenas alguns exemplos, disse o diretor de engenharia do Google, Ray Kurzweil, aos participantes da Cebit Global Conference, em março.
"Se o seu chefe lhe disser algo uma ou duas vezes, você pode realmente aprender com isso. Essa é uma força de inteligência humana, ainda distante das máquinas", disse ele.
Mas no campo da Deep Learning há um ditado que diz que "a vida começa em um bilhão de exemplos".
Em outras palavras, as tecnologias de aprendizagem mecânica, como redes neurais profundas, precisam observar uma tarefa um bilhão de vezes para aprender a realizá-la melhor do que um ser humano.
Encontrar milhares de milhões de exemplos de algo é um problema em si: os desenvolvedores do AlphaGo examinaram a Internet para registros de milhares de partidas de Go entre humanos para fornecer o treinamento inicial para sua rede neural de 13 camadas. Como ela se tornou mais experiente, ela joga contra outras versões de si mesmo para gerar novos dados de jogo.
A AlphaGo aprendeu usando dois tipos de máquina de aprendizagem. Os jogos humanos foram analisados através da aprendizagem supervisionada, na qual os dados de entrada são marcados com a resposta que a rede neural deve aprender - neste caso, que jogar esses movimentos leva à vitória. E, depois, jogando contra si, em um tipo de reforço aprendizado. O objetivo de ganhar o jogo ainda era explícito, mas não havia dados de entrada. O AlphaGo foi programado para gerar e avaliar isso por si mesmo, usando uma segunda rede neural em que os neurônios começaram com as mesmas ponderações que a rede de aprendizagem supervisionada, mas modificou-os gradualmente com as descobertas que fez sobre estratégias de jogadores humanos.
Uma terceira técnica, a aprendizagem não supervisionada, é útil nos negócios, mas menos útil nos jogos. Neste modo, nenhuma informação é dada para a rede neural sobre o seu objetivo, mas é deixado que ela explore livremente um conjunto de dados por conta própria, agrupando os dados em categorias e identificando as ligações entre eles. Machine Learning usada desta forma torna-se apenas mais uma ferramenta de análise: pode identificar padrões e deixar que um jogo se desenrole e termine de várias maneiras, deixando o julgamento do que fazer em cada jogada para um supervisor humano.
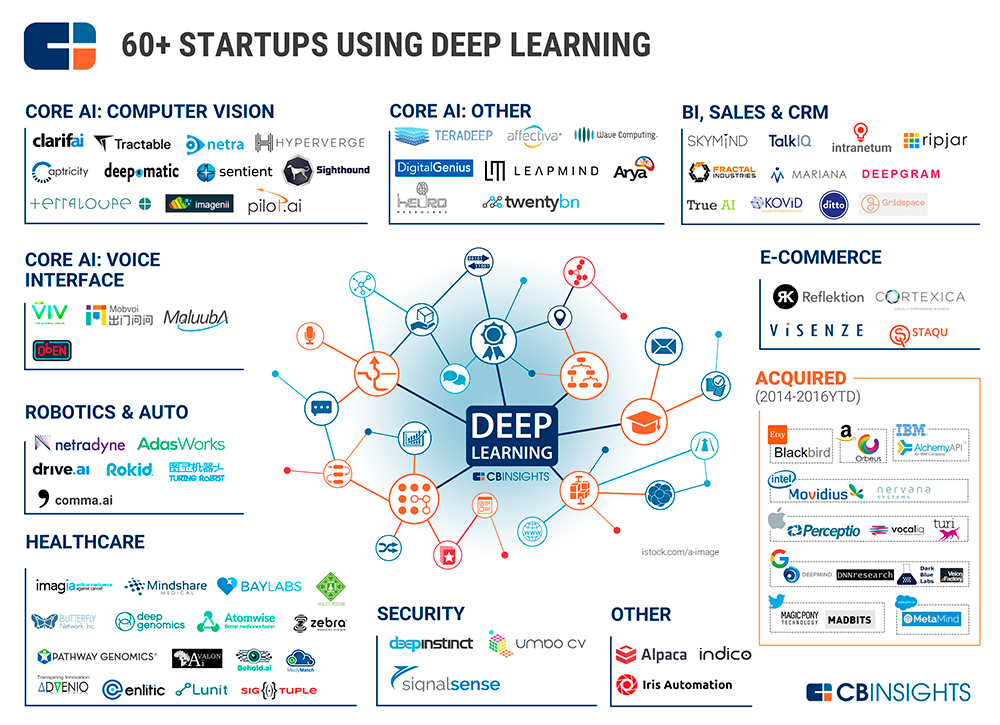
Há muitas empresas, grandes e pequenas, que oferecem alguns dos blocos de construção Inteligência Artificial para uso em aplicativos e serviços corporativos. As empresas menores, muitas vezes focam em tarefas específicas ou em indústrias específica.
Graças em grande parte à publicidade em torno de sua oferta Watson , a IBM é um dos primeiros vendedores de Inteligência Artificial a saltar à mente - embora prefira o termo "computação cognitiva".
O Watson inclui ferramentas para criar chatbots, descobrir padrões e estrutura em dados textuais e extrair conhecimento de texto não estruturado. A IBM também treinou alguns de seus serviços Watson com informações específicas de determinados setores, adaptando a oferta para usuários em serviços de saúde, educação, serviços financeiros, comércio, marketing e operações de cadeia de suprimentos.
A IBM e seus parceiros podem ajudar a integrar a Inteligência Artificial aos processos de negócios existentes, ou os desenvolvedores podem pesquisar por si mesmos, já que a maioria das ferramentas também está disponível como APIs no portal de serviços em nuvem Bluemix.
Cognitivo também é o termo preferido da Microsoft. Sob a marca Microsoft Cognitive Services, a empresa oferece aos desenvolvedores acesso às APIs para incorporar tecnologias de aprendizado de máquinas em suas próprias aplicações. Estas incluem ferramentas para converter a fala em texto e compreender a sua intenção; detectar e corrigir erros ortográficos em um texto; traduzir fala e texto; e explorar as relações entre os trabalhos acadêmicos, seus autores e as revistas que os publicam. Há também um serviço para construir chatbots e conectá-los ao Slack, Twitter, Office 365 e outros serviços, chamado Bot Framework . A Microsoft também oferece um kit de ferramentas de código aberto que as empresas podem baixar para treinar seus sistemas de aprendizagem profunda usando seus próprios conjuntos de dados macivos.
Na Build, no início de maio, ofereceu versões de produção de serviços anteriormente disponíveis somente na pré-visualização, incluindo uma API de marcação de rosto e um moderador de conteúdo automatizado que pode aprovar ou bloquear texto, imagens e vídeos, encaminhando casos difíceis para revisão de humanos. Há também um novo serviço de reconhecimento de imagem personalizado que as empresas podem treinar para reconhecer objetos de interesse para eles, como peças usadas em uma fábrica.
A Google oferece muitas das tecnologias de aprendizado de máquinas que usa internamente como parte de sua plataforma Google Cloud . Os sistemas estão disponíveis ou já treinados para tarefas específicas ou para serem treinados a partir de dados dos próprios usuários, que incluem análise de imagem, texto e vídeo, reconhecimento de voz e tradução. Há também uma ferramenta de processamento de linguagem natural para extrair sentimento e significado do texto que pode ser usado em chatbots e call centers. Há ainda uma ferramenta de pesquisa de trabalho super-focada que tenta combinar candidatos a emprego com vagas com base em sua localização, experiência e habilidades.
Quanto à Amazon Web Services, ela permite que as empresas criem novas "habilidades" ou aplicativos controlados por voz para o Alexa, o assistente digital embutido nos dispositivos Amazon Echo, e oferece muitas das tecnologias por trás do Alexa "como um serviço". Sua oferta mais recente é dirigida aos call centers, o Amazon Connect , cobrado por chamada e por minuto. Oferece integrações com os serviços de reconhecimento e compreensão de fala da Amazon, permitindo que as empresas criem sistemas de resposta de voz (IVR) mais sofisticados.
E o que está por vir?
Esses serviços estão todos em produção, mas há muitos outros em compasso de espera.
A Microsoft, por exemplo, já convida as empresas a testarem versões de "pré-visualização" de vários outros serviços, incluindo uma ferramenta de análise de imagem chamada Emotion API, que pode identificar a emoção expressa por rostos em fotos, atribuindo probabilidades relativas à raiva, desprezo, desgosto, medo, felicidade, tristeza e surpresa. (Você pode enviar um selfie para experimentá-la.) Melhorias para as ferramentas de voz da empresa também estão no horizonte. Elas permitirão às empresas ajustar o motor para regiões específicas ou ambientes (Custom Speech Service), e até mesmo para reconhecer o orador.
Uma nova ferramenta chamada QnA Maker extrai perguntas freqüentes de um texto e as serve como respostas para um chatbot. Os resultados até agora são um tanto toscos, não raro mais por culpa dos textos uados como fonte pelo fabricante de QnA.
Na conferência Google Cloud Next '17, realizada em março na cidade de São Francisco, a empresa revelou um teste beta privado de sua API Cloud Video Intelligence, que permitirá aos testadores encontrar clipes de vídeo relevantes, procurando por substantivos ou verbos descrevendo o conteúdo. O Google espera estimular uma maior demanda por seus serviços com uma nova máquina que está funcionando com as empresas de capital de risco Data Collective e Emergence Capital e com a abertura do Laboratório de Soluções Avançadas de Machine Learning em Mountain View, Califórnia, onde os clientes poderão trabalhar com especialistas do Google para aplicar a aprendizagem de máquina para seus próprios problemas.
Mais recentemente, durante a Google I/O, a empresa mostrou a plataforma TensorFlow Lite para telefones celulares e um processador mais robusto para a execução de cargas de trabalho de aprendizagem de máquinas, a Cloud TPU (Tensor Processing Unit). El também publicou detalhes de algumas das APIs de aprendizado de máquinas que tem usando internamente.
As grandes empresas não têm um monopólio sobre a ipesquisa em Inteligência Artificial, mas a concorrência por pessoal qualificado é feroz. O Facebook, que tem sua própria divisão interna de pesquisa, organiza eventos internos de treinamento para aumentar a conscientização da aprendizagem de máquinas entre seus funcionários.
Algumas das maiores empresas envolvidas na pesquisa da IA estão demonstrando disposição para publicar seus resultados e liberar grande parte de seu código sob licenças de código aberto . Mesmo a notoriamente fechada Apple publicou seu primeiro trabalho de pesquisa no final do ano passado.
Mas nenhuma delas tem revelado as jóias da coroa. Esses kits de ferramentas de aprendizado de máquinas e serviços em nuvem, por melhor que sejam, ainda são redes neurais não treinadas, tão útil para uma empresa como uma escola abandonada.
A experiência conta. E o que Google, Facebook, Amazon, e até mesmo a Apple e Microsoft, estão fazendo hoje é reunir bilhões de pequenos exemplos que podem formatar futuras ofertas.
Naturalmente, um bilhão de exemplos nem sempre podem ser necessários: os computadores podem aprender a fazer algumas coisas quase tão bem quanto um humano com muito menos dados, e para muitas tarefas hoje em dia, quase pode ser bom o suficiente, especialmente se o computador for capaz de lidar com situações que não necessitem de um supervisor humano.
Bem ao seu lado
É com isso que muitas das organizações que constróem chatbots com Inteligência Artificial estão contando. Elas têm muito menos que um bilhão de pontos de dados para lidar, e ainda esperam que serviços como o QnA Maker, da Microsoft, os ajudem a atender os clientes de novas maneiras.
E aqui é preciso levantar um risco que as empresas enfrentam ao usar os serviços de nuvem. Entre elas, a privacidade.
Uma pesquisa recente da Accenture descobriu que, nos próximos três anos, 78% dos bancos dos EUA contarão com a Inteligência Artificial para garantir uma experiência mais humana quando lidam com sistemas automatizados e 76% deles esperam competir em sua capacidade de tornar a tecnologia invisível para os clientes.
No entanto, nos próximos dois ou três anos, os sistemas de aprendizado de máquinas serão mais eficazes quando usados para filtrar e priorizar as decisões para os seres humanos
imagens